1.1聚集索引与辅助索引


# InnoDB存储引擎表示索引组织表,即表中数据按照主键顺序存放。而聚集索引(clustered index)就是按照每张表的主键构造一棵B+树,# 同时叶子结点存放的即为整张表的行记录数据,也将聚集索引的叶子结点称为数据页。聚集索引的这个特性决定了索引组织表中数据也是索引的一部分。# 如果未定义主键,MySQL取第一个唯一索引(unique)而且只含非空列(NOT NULL)作为主键,InnoDB使用它作为聚簇索引,如果不存在这样的列的话# InnoDB就自己产生一个这样的ID值,它有六个字节,而且是隐藏的,使其作为聚簇索引# 由于数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索引# 辅助索引# 在一些查询的时候,如果没有办法使用到聚集索引(主键的话),例如where name = 'panzhenwei'# 这是就可以借助辅助索引(由唯一键,index键组成)# 与聚集索引的区别是:辅助索引的叶子节点不包含行记录的全部数据# 辅助索引包含的相当于是如果以name作为索引键的话,则为{'name字段',name的值,主键id值}# 一张表可以有多个辅助索引,在查找的时候,通过辅助索引查找到对应的项,再通过这个索引键对应的主键的id值# 获取整行的记录
1.2 索引的简单操作
# 常见的索引方式# 普通索引 index## 唯一索引:# -主键索引PRIMARY KEY:加速查找+约束(不为空、不能重复)# -唯一索引UNIQUE:加速查找+约束(不能重复)## 联合索引:# -PRIMARY KEY(id,name):联合主键索引# -UNIQUE(id,name):联合唯一索引# -INDEX(id,name):联合普通索引# 索引的创建# 方法1:在创建表的时候顺便创建索引# create table 表名(字段名 数据类型 [约束条件] index/unique/ [索引名称] (作为索引的字段名) );# create table index2 (id int primary key , name char(10),age int, index cisco (age));## 方法2: 在已经创建的表创建索引;# create unique/index 索引名 on 表名(字段名称)# create index cisco on index1(age)## 方法3:在已经创建的表上通过修改的方式,创建一个索引键# alter table 表名 add unique/index 索引名 (字段名)# alter table index3 add index cisco (age);# 删除索引:DROP INDEX 索引名 ON 表名字;show index from 表名show keys from 表名# 如果表在已经存在了大量的数据的话,这时候才使用命令建立索引的话,建立索引是有点慢的,但在建立索引之后的关于# 对应项的查询的速度会明显加快# alter table 表名 add primary key (添加主键的字段的名称)# alter table 表名 drop primary key# 联合索引# 新建表建立联合索引# create table 表名(a int ,b,int , primary key(a),key 索引名 (a,b));# 或者# create table 表名(a int ,b,int , primary key(a),index 索引名 (a,b));# 在已经建立的表中添加索引的条件# alter table tt add index 索引名 (a,b)# 或# alter table tt add key 索引名 (a,b )# 使用的原则:# 例如select * from tt where a = xxx and b = xxx# select * from tt where a = xxx# 但是select * from tt wehre b = xxx 用不到联合索引## 所以:注意建立联合索引的一个原则:索引是有个最左匹配的原则的,所以建联合索引的时候,将区分度高的放在最左边,# 依次排下来,范围查询的条件尽可能的往后边放。# 覆盖索引# InnoDB存储引擎支持覆盖索引(covering index,或称索引覆盖),即从辅助索引中就可以得到查询记录,而不需要查询聚集索引中的记录。
1.3 索引创建需要注意的地方
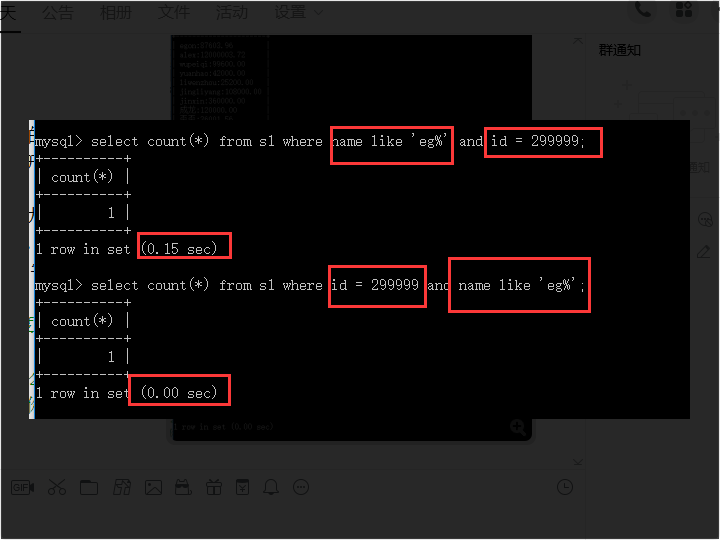
# 缺点,建立索引之后,每插入一条数据,索引记录都会重建,导致数据写入会比正常的慢# 建立索引和查找的时候需要注意的点# 1.在查找的时候,尽量少些使用一个范围比较大或者是条件不明确的符号# 例如:>、>=、<、<=、!= 、between...and...、like# 2.设置查找条件的时候,尽量将含有索引的条件放在左边(最左前缀匹配原则)# 3.建立索引的时候使用区分度比较大的列作为索引# 对于and 条件的查找# mysql会按照联合索引,从左到右的顺序找一个区分度高的索引字段(这样便可以快速锁定很小的范围),加速查询,先执行区分度比较到的索引的字段## 对于or的条件查找# 只要一个匹配成功就行,所以对于连续多个or:mysql会按照条件的顺序,从左到右依次判断# 对于组合索引mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配# (指的是范围大了,有索引速度也慢),比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,# 如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。# - 避免使用select *# - count(1)或count(列) 代替 count(*)# - 创建表时尽量时 char 代替 varchar# - 表的字段顺序固定长度的字段优先# - 组合索引代替多个单列索引(经常使用多个条件查询时)# - 尽量使用短索引# - 使用连接(JOIN)来代替子查询(Sub-Queries)# - 连表时注意条件类型需一致# - 索引散列值(重复少)不适合建索引,例:性别不适合
从左往右,范围小的优先,具有索引的优先,有利于加快查找速度